データベースへの接続
Superset には、データベースへの接続機能はバンドルされていません。Superset をデータベースに接続する際の主な手順は、環境に適切なデータベースドライバーをインストールすることです。
メタデータデータベースとして使用するデータベースに必要なパッケージと、Superset を介してアクセスするデータベースへの接続に必要なパッケージをインストールする必要があります。Superset のメタデータデータベースのセットアップに関する情報は、インストールに関するドキュメント(Docker Compose、Kubernetes)を参照してください。
このドキュメントでは、一般的に使用されるデータベースエンジン用のさまざまなドライバーへのポインターを維持しようとしています。
データベースドライバーのインストール
Superset では、接続する各データベースエンジンに対して、Python のDB-API データベースドライバーとSQLAlchemy ダイアレクトがインストールされている必要があります。
Superset の設定に新しいデータベースドライバーをインストールする方法の詳細については、こちらを参照してください。
サポートされているデータベースと依存関係
推奨されるパッケージの一部を以下に示します。Superset と互換性のあるバージョンについては、pyproject.toml を参照してください。
データベース | PyPI パッケージ | 接続文字列 |
|---|---|---|
| AWS Athena | pip install pyathena[pandas]、pip install PyAthenaJDBC | awsathena+rest://{access_key_id}:{access_key}@athena.{region}.amazonaws.com/{schema}?s3_staging_dir={s3_staging_dir}&... |
| AWS DynamoDB | pip install pydynamodb | dynamodb://{access_key_id}:{secret_access_key}@dynamodb.{region_name}.amazonaws.com?connector=superset |
| AWS Redshift | pip install sqlalchemy-redshift | redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name> |
| Apache Doris | pip install pydoris | doris://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database> |
| Apache Drill | pip install sqlalchemy-drill | drill+sadrill:// JDBC の場合は drill+jdbc:// |
| Apache Druid | pip install pydruid | druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql |
| Apache Hive | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Apache Impala | pip install impyla | impala://{hostname}:{port}/{database} |
| Apache Kylin | pip install kylinpy | kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2> |
| Apache Pinot | pip install pinotdb | pinot://BROKER:5436/query?server=http://CONTROLLER:5983/ |
| Apache Solr | pip install sqlalchemy-solr | solr://{username}:{password}@{hostname}:{port}/{server_path}/{collection} |
| Apache Spark SQL | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Ascend.io | pip install impyla | ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true |
| Azure MS SQL | pip install pymssql | mssql+pymssql://UserName@presetSQL:TestPassword@presetSQL.database.windows.net:1433/TestSchema |
| ClickHouse | pip install clickhouse-connect | clickhousedb://{username}:{password}@{hostname}:{port}/{database} |
| CockroachDB | pip install cockroachdb | cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable |
| Couchbase | pip install couchbase-sqlalchemy | couchbase://{username}:{password}@{hostname}:{port}?truststorepath={ssl certificate path} |
| Denodo | pip install denodo-sqlalchemy | denodo://{username}:{password}@{hostname}:{port}/{database} |
| Dremio | pip install sqlalchemy_dremio | dremio+flight://{username}:{password}@{host}:32010、多くの場合、?UseEncryption=true/false が役立ちます。レガシーODBCの場合: dremio+pyodbc://{username}:{password}@{host}:31010 |
| Elasticsearch | pip install elasticsearch-dbapi | elasticsearch+http://{user}:{password}@{host}:9200/ |
| Exasol | pip install sqlalchemy-exasol | exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC |
| Google BigQuery | pip install sqlalchemy-bigquery | bigquery://{project_id} |
| Google Sheets | pip install shillelagh[gsheetsapi] | gsheets:// |
| Firebolt | pip install firebolt-sqlalchemy | firebolt://{client_id}:{client_secret}@{database}/{engine_name}?account_name={name} |
| Hologres | pip install psycopg2 | postgresql+psycopg2://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| IBM Db2 | pip install ibm_db_sa | db2+ibm_db:// |
| IBM Netezza Performance Server | pip install nzalchemy | netezza+nzpy://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| MySQL | pip install mysqlclient | mysql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| OceanBase | pip install oceanbase_py | oceanbase://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| Oracle | pip install cx_Oracle | oracle:// |
| PostgreSQL | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| Presto | pip install pyhive | presto:// |
| Rockset | pip install rockset-sqlalchemy | rockset://<api_key>:@<api_server> |
| SAP Hana | pip install hdbcli sqlalchemy-hana または pip install apache-superset[hana] | hana://{username}:{password}@{host}:{port} |
| StarRocks | pip install starrocks | starrocks://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database> |
| Snowflake | pip install snowflake-sqlalchemy | snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse} |
| SQLite | 追加のライブラリは不要 | sqlite://path/to/file.db?check_same_thread=false |
| SQL Server | pip install pymssql | mssql+pymssql:// |
| Teradata | pip install teradatasqlalchemy | teradatasql://{user}:{password}@{host} |
| TimescaleDB | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>:<Port>/<Database Name> |
| Trino | pip install trino | trino://{username}:{password}@{hostname}:{port}/{catalog} |
| Vertica | pip install sqlalchemy-vertica-python | vertica+vertica_python://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| YugabyteDB | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
他にも多くのデータベースがサポートされています。主な基準は、機能する SQLAlchemy ダイアレクトと Python ドライバーが存在することです。「sqlalchemy + (データベース名)」というキーワードで検索すると、適切な場所にたどり着くはずです。
お使いのデータベースまたはデータエンジンがリストにないものの、SQL インターフェイスが存在する場合は、Superset GitHub リポジトリで問題を提出してください。ドキュメント化とサポートに取り組むことができます。
Superset 統合用のデータベースコネクターを構築する場合は、次のチュートリアルをご覧ください。
Docker イメージへのドライバーのインストール
Superset では、接続する追加のデータベースタイプごとに Python データベースドライバーがインストールされている必要があります。
この例では、MySQL コネクターライブラリのインストール方法について説明します。コネクターライブラリのインストールプロセスは、他のすべてのライブラリでも同じです。
1. 必要なドライバーの特定
データベースドライバーのリストを参照して、データベースへの接続に必要な PyPI パッケージを見つけてください。この例では、MySQL データベースに接続するので、mysqlclient コネクターライブラリが必要になります。
2. コンテナへのドライバーのインストール
mysqlclient ライブラリを Superset Docker コンテナにインストールする必要があります(ホストマシンにインストールされているかどうかは関係ありません)。docker exec -it <container_name> bash を使用して実行中のコンテナに入り、そこで pip install mysqlclient を実行することもできますが、これは永続的に保持されません。
この問題に対処するために、Superset docker compose デプロイメントでは、requirements-local.txt ファイルの規則を使用します。このファイルにリストされているすべてのパッケージは、実行時に PyPI からコンテナにインストールされます。このファイルは、ローカル開発の目的で Git によって無視されます。
docker-compose.yml または docker-compose-non-dev.yml ファイルがあるディレクトリに存在する docker というサブディレクトリに requirements-local.txt ファイルを作成します。
# Run from the repo root:
touch ./docker/requirements-local.txt
上記の手順で特定したドライバーを追加します。テキストエディタを使用するか、コマンドラインから次のように実行できます。
echo "mysqlclient" >> ./docker/requirements-local.txt
ストック(カスタマイズされていない)Supersetイメージを実行している場合、作業は完了です。docker compose -f docker-compose-non-dev.yml upでSupersetを起動すると、ドライバーが存在しているはずです。
docker exec -it <container_name> bashで実行中のコンテナに入り、pip freezeを実行することで、ドライバーの存在を確認できます。PyPIパッケージは、出力されたリストに含まれているはずです。
カスタマイズされたDockerイメージを実行している場合は、新しいドライバーを組み込んでローカルイメージをリビルドしてください。
docker compose build --force-rm
Dockerイメージのリビルドが完了したら、docker compose upを実行してSupersetを再起動します。
3. MySQLへの接続
コンテナにMySQLドライバーがインストールされたので、SupersetのWeb UIからデータベースに接続できるはずです。
管理者ユーザーとして、Settings -> Data: Database Connections に移動し、+DATABASE ボタンをクリックします。そこから、データベース接続UIの使用ページの手順に従ってください。
Supersetドキュメントの特定のデータベースタイプのページを参照して、接続文字列と入力する必要があるその他のパラメーターを決定してください。たとえば、MySQLページでは、ローカルのMySQLデータベースへの接続文字列は、セットアップがLinuxで実行されているかMacで実行されているかによって異なることがわかります。
「Test Connection」ボタンをクリックすると、「Connection looks good!」というポップアップメッセージが表示されるはずです。
4. トラブルシューティング
テストが失敗した場合は、Dockerログでエラーメッセージを確認してください。Supersetはデータベースへの接続にSQLAlchemyを使用しています。データベースの接続文字列をトラブルシューティングするには、Supersetアプリケーションコンテナまたはホスト環境でPythonを起動し、目的のデータベースに直接接続してデータを取得してみてください。これにより、問題の切り分けのためにSupersetを除外できます。
Supersetに接続させたいデータベースの種類ごとにこのプロセスを繰り返してください。
データベース固有の手順
Ascend.io
Ascend.ioへの推奨コネクターライブラリはimpylaです。
予期される接続文字列は、次のようにフォーマットされます。
ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true
Apache Doris
sqlalchemy-dorisライブラリは、SQLAlchemyを通じてApache Dorisに接続するための推奨される方法です。
接続文字列を作成するには、次の設定値が必要です。
- User: ユーザー名
- Password: パスワード
- Host: Doris FE ホスト
- Port: Doris FE ポート
- Catalog: カタログ名
- Database: データベース名
接続文字列は次のようになります。
doris://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>
AWS Athena
PyAthenaJDBC
PyAthenaJDBCは、Amazon Athena JDBCドライバ用のPython DB 2.0準拠ラッパーです。
Amazon Athenaの接続文字列は次のとおりです。
awsathena+jdbc://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
接続文字列を作成する際には、次のようにエスケープとエンコードが必要になることに注意してください。
s3://... -> s3%3A//...
PyAthena
PyAthenaライブラリ(Javaは不要)を次の接続文字列で使用することもできます。
awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
PyAthenaライブラリでは、SupersetのAthenaデータベース接続UIの[ADVANCED] --> [Other] --> [ENGINE PARAMETERS]に次のパラメーターを追加して定義することで、特定のIAMロールを引き受けることもできます。
{
"connect_args": {
"role_arn": "<role arn>"
}
}
AWS DynamoDB
PyDynamoDB
PyDynamoDBは、Amazon DynamoDB用のPython DB API 2.0 (PEP 249)クライアントです。
Amazon DynamoDBの接続文字列は次のとおりです。
dynamodb://{aws_access_key_id}:{aws_secret_access_key}@dynamodb.{region_name}.amazonaws.com:443?connector=superset
詳細なドキュメントについては、PyDynamoDB WIKIをご覧ください。
AWS Redshift
sqlalchemy-redshiftライブラリは、SQLAlchemyを通じてRedshiftに接続するための推奨される方法です。
このダイアレクトを正しく機能させるには、redshift_connectorまたはpsycopg2のいずれかが必要です。
接続文字列を作成するには、次の値を設定する必要があります。
- ユーザー名: ユーザー名
- パスワード: DBパスワード
- データベースホスト: AWSエンドポイント
- データベース名: データベース名
- ポート: デフォルト 5439
psycopg2
SQLALCHEMY URIは次のようになります。
redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>
redshift_connector
SQLALCHEMY URIは次のようになります。
redshift+redshift_connector://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>
RedshiftクラスターでIAMベースの資格情報を使用する:
Amazon Redshiftクラスターは、一時的なIAMベースのデータベースユーザー資格情報の生成もサポートしています。
SupersetアプリのIAMロールには、redshift:GetClusterCredentials操作を呼び出す権限が必要です。
SupersetのRedshiftデータベース接続UIの[ADVANCED] --> [Others] --> [ENGINE PARAMETERS]で、次の引数を定義する必要があります。
{"connect_args":{"iam":true,"database":"<database>","cluster_identifier":"<cluster_identifier>","db_user":"<db_user>"}}
また、SQLALCHEMY URIはredshift+redshift_connector://に設定する必要があります。
RedshiftサーバーレスでIAMベースの資格情報を使用する:
Redshiftサーバーレスは、IAMロールを使用した接続をサポートしています。
SupersetアプリのIAMロールには、Redshiftサーバーレスワークグループに対するredshift-serverless:GetCredentialsおよびredshift-serverless:GetWorkgroup権限が必要です。
SupersetのRedshiftデータベース接続UIの[ADVANCED] --> [Others] --> [ENGINE PARAMETERS]で、次の引数を定義する必要があります。
{"connect_args":{"iam":true,"is_serverless":true,"serverless_acct_id":"<aws account number>","serverless_work_group":"<redshift work group>","database":"<database>","user":"IAMR:<superset iam role name>"}}
ClickHouse
SupersetでClickHouseを使用するには、clickhouse-connectPythonライブラリをインストールする必要があります。
Docker Composeを使用してSupersetを実行している場合は、./docker/requirements-local.txtファイルに以下を追加してください。
clickhouse-connect>=0.6.8
ClickHouseの推奨コネクターライブラリは、clickhouse-connectです。
予期される接続文字列は、次のようにフォーマットされます。
clickhousedb://<user>:<password>@<host>:<port>/<database>[?options…]clickhouse://{username}:{password}@{hostname}:{port}/{database}
以下は、実際の接続文字列の具体的な例です。
clickhousedb://demo:demo@github.demo.trial.altinity.cloud/default?secure=true
コンピューターでローカルにClickhouseを使用している場合は、パスワードなしでデフォルトユーザーを使用するhttpプロトコルURLを使用できます(接続を暗号化しません)。
clickhousedb:///default
CockroachDB
CockroachDBの推奨コネクターライブラリは、sqlalchemy-cockroachdbです。
予期される接続文字列は、次のようにフォーマットされます。
cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable
Couchbase
CouchbaseのSuperset接続は、Couchbase AnalyticsとCouchbase Columnarの2つのサービスをサポートするように設計されています。Couchbaseの推奨コネクターライブラリは、couchbase-sqlalchemyです。
pip install couchbase-sqlalchemy
予期される接続文字列は、次のようにフォーマットされます。
couchbase://{username}:{password}@{hostname}:{port}?truststorepath={certificate path}?ssl={true/false}
CrateDB
CrateDBの推奨コネクターライブラリは、crateです。このライブラリのextrasもインストールする必要があります。requirementsファイルに次のようなテキストを追加することをお勧めします。
crate[sqlalchemy]==0.26.0
予期される接続文字列は、次のようにフォーマットされます。
crate://crate@127.0.0.1:4200
Databend
Databendの推奨コネクターライブラリは、databend-sqlalchemyです。Supersetはdatabend-sqlalchemy>=0.2.3でテストされています。
推奨される接続文字列は次のとおりです。
databend://{username}:{password}@{host}:{port}/{database_name}
以下は、SupersetがDatabendデータベースに接続する場合の接続文字列の例です。
databend://user:password@localhost:8000/default?secure=false
Databricks
Databricksは現在、sqlalchemy-databricksダイアレクトで使用できるネイティブDB API 2.0ドライバーdatabricks-sql-connectorを提供しています。両方をインストールするには、次のようにします。
pip install "apache-superset[databricks]"
Hiveコネクターを使用するには、クラスターから次の情報が必要です。
- サーバーホスト名
- ポート
- HTTPパス
これらは、[構成] -> [詳細オプション] -> [JDBC/ODBC]で確認できます。
[設定] -> [ユーザー設定] -> [アクセストークン]からアクセストークンも必要です。
この情報をすべて入手したら、「Databricks Native Connector」タイプのデータベースを追加し、次のSQLAlchemy URIを使用します。
databricks+connector://token:{access_token}@{server_hostname}:{port}/{database_name}
また、[その他] -> [エンジンパラメーター]に次の構成をHTTPパスとともに
{
"connect_args": {"http_path": "sql/protocolv1/o/****"}
}
旧ドライバー
元々Supersetはdatabricks-dbapiを使用してDatabricksに接続していました。公式のDatabricksコネクターで問題が発生している場合は、試してみることをお勧めします。
pip install "databricks-dbapi[sqlalchemy]"
databricks-dbapiを使用する場合、Databricksに接続する方法は2つあります。Hiveコネクターを使用する方法とODBCコネクターを使用する方法です。どちらの方法も同様に機能しますが、SQLエンドポイントへの接続にはODBCのみを使用できます。
Hive
Hiveクラスターに接続するには、Supersetで「Databricks Interactive Cluster」タイプのデータベースを追加し、次のSQLAlchemy URIを使用します。
databricks+pyhive://token:{access_token}@{server_hostname}:{port}/{database_name}
また、[その他] -> [エンジンパラメーター]に次の構成をHTTPパスとともに
{"connect_args": {"http_path": "sql/protocolv1/o/****"}}
ODBC
ODBCを使用するには、まずプラットフォーム用のODBCドライバーをインストールする必要があります。
通常の接続の場合は、使用事例に応じて、データベースとして「Databricks Interactive Cluster」または「Databricks SQL Endpoint」を選択した後、これをSQLAlchemy URIとして使用します。
databricks+pyodbc://token:{access_token}@{server_hostname}:{port}/{database_name}
接続引数の場合は、
{"connect_args": {"http_path": "sql/protocolv1/o/****", "driver_path": "/path/to/odbc/driver"}}
ドライバーパスは次のようになります。
/Library/simba/spark/lib/libsparkodbc_sbu.dylib(Mac OS)/opt/simba/spark/lib/64/libsparkodbc_sb64.so(Linux)
SQLエンドポイントへの接続の場合、エンドポイントのHTTPパスを使用する必要があります。
{"connect_args": {"http_path": "/sql/1.0/endpoints/****", "driver_path": "/path/to/odbc/driver"}}
Denodo
Denodoの推奨コネクターライブラリは、denodo-sqlalchemyです。
予期される接続文字列は、次のようにフォーマットされます(デフォルトポートは9996です)。
denodo://{username}:{password}@{hostname}:{port}/{database}
Dremio
Dremioの推奨コネクターライブラリは、sqlalchemy_dremioです。
ODBCの予期される接続文字列(デフォルトポートは31010)は、次のようにフォーマットされます。
dremio+pyodbc://{username}:{password}@{host}:{port}/{database_name}/dremio?SSL=1
Arrow Flightの予期される接続文字列(Dremio 4.9.1以降。デフォルトポートは32010)は、次のようにフォーマットされます。
dremio+flight://{username}:{password}@{host}:{port}/dremio
Dremioによるこちらのブログ記事には、SupersetをDremioに接続する際の追加の役立つ手順がいくつか記載されています。
Apache Drill
SQLAlchemy
Apache Drillに接続する推奨方法はSQLAlchemy経由です。sqlalchemy-drillパッケージを使用できます。
完了したら、RESTインターフェースまたはJDBCのいずれかを使用して、2つの方法でDrillに接続できます。JDBC経由で接続する場合は、Drill JDBCドライバーがインストールされている必要があります。
Drillの基本的な接続文字列は次のようになります。
drill+sadrill://<username>:<password>@<host>:<port>/<storage_plugin>?use_ssl=True
埋め込みモードでローカルマシンで実行されているDrillに接続するには、次の接続文字列を使用できます。
drill+sadrill://:8047/dfs?use_ssl=False
JDBC
JDBCを介してDrillに接続するのはより複雑であるため、こちらのチュートリアルに従うことをお勧めします。
接続文字列は次のようになります。
drill+jdbc://<username>:<password>@<host>:<port>
ODBC
DrillをODBC経由で操作する方法については、Apache DrillのドキュメントとGitHub READMEを読むことをお勧めします。
Apache Druid
DruidへのネイティブコネクタはSupersetに付属していますが(DRUID_IS_ACTIVEフラグの背後にあります)、pydruidライブラリで利用可能なSQLAlchemy/DBAPIコネクタに徐々に置き換えられています。
接続文字列は次のようになります。
druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql
この接続文字列の主要なコンポーネントの内訳を以下に示します。
User: データベースへの接続に必要な認証情報のユーザー名部分Password: データベースへの接続に必要な認証情報のパスワード部分Host: データベースを実行しているホストマシンのIPアドレス(またはURL)Port: データベースが実行されているホストマシンで公開されている特定のポート
Druid接続のカスタマイズ
Druidへの接続を追加する際、データベースを追加フォームでいくつかの異なる方法で接続をカスタマイズできます。
カスタム証明書
Druidへの新しいデータベース接続を構成する際、ルート証明書フィールドに証明書を追加できます。

カスタム証明書を使用すると、pydruidは自動的にhttpsスキームを使用します。
SSL検証の無効化
SSL検証を無効にするには、追加フィールドに以下を追加します。
engine_params:
{"connect_args":
{"scheme": "https", "ssl_verify_cert": false}}
集計
一般的な集計またはDruidメトリクスを定義して、Supersetで使用できます。最初でより簡単なユースケースは、データソースの編集ビュー(ソース -> Druidデータソース -> [データソース] -> 編集 -> [タブ] Druid列のリスト)で公開されているチェックボックスマトリックスを使用することです。
GroupByおよびフィルタリング可能チェックボックスをクリックすると、[探索]ビューで関連するドロップダウンに列が表示されるようになります。Count Distinct、Min、Max、またはSumをチェックすると、データソースを保存すると、Druidメトリクスのリストタブに新しいメトリクスが作成されます。
これらのメトリクスを編集すると、そのJSON要素がDruid集計定義に対応していることに気付くでしょう。Druidのドキュメントに従って、Druidメトリクスのリストタブから手動で独自の集計を作成できます。
事後集計
Druidは事後集計をサポートしており、これはSupersetで機能します。手動で集計を作成するのと同じようにメトリクスを作成しますが、メトリックタイプとしてpostaggを指定する必要があります。次に、JSONフィールドに(Druidドキュメントで指定されているように)有効なjson事後集計定義を提供する必要があります。
Elasticsearch
Elasticsearchの推奨コネクタライブラリはelasticsearch-dbapiです。
Elasticsearchの接続文字列は次のようになります。
elasticsearch+http://{user}:{password}@{host}:9200/
HTTPSの使用
elasticsearch+https://{user}:{password}@{host}:9200/
Elasticsearchのデフォルトの制限は10000行であるため、クラスターでこの制限を増やすか、Supersetの行制限を構成で設定できます。
ROW_LIMIT = 10000
たとえば、SQL Labで複数のインデックスをクエリできます。
SELECT timestamp, agent FROM "logstash"
ただし、複数のインデックスの可視化を使用するには、クラスターにエイリアスインデックスを作成する必要があります。
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "logstash-**", "alias" : "logstash_all" } }
]
}
次に、エイリアス名logstash_allを使用してテーブルを登録します。
タイムゾーン
デフォルトでは、SupersetはElasticsearchクエリにUTCタイムゾーンを使用します。タイムゾーンを指定する必要がある場合は、データベースを編集し、[その他] > [エンジンのパラメータ]で指定したタイムゾーンの設定を入力してください。
{
"connect_args": {
"time_zone": "Asia/Shanghai"
}
}
タイムゾーンの問題について注意すべきもう1つの問題は、elasticsearch7.8より前は、文字列をDATETIMEオブジェクトに変換したい場合、CAST関数を使用する必要がありましたが、この関数はtime_zone設定をサポートしていません。したがって、elasticsearch7.8以降のバージョンにアップグレードすることをお勧めします。elasticsearch7.8以降は、DATETIME_PARSE関数を使用してこの問題を解決できます。DATETIME_PARSE関数はtime_zone設定をサポートするためのものであり、ここで[その他] > [バージョン]設定にElasticsearchのバージョン番号を入力する必要があります。Supersetは変換にDATETIME_PARSE関数を使用します。
SSL検証の無効化
SSL検証を無効にするには、SQLALCHEMY URIフィールドに以下を追加します。
elasticsearch+https://{user}:{password}@{host}:9200/?verify_certs=False
Exasol
Exasolの推奨コネクタライブラリはsqlalchemy-exasolです。
Exasolの接続文字列は次のようになります。
exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC
Firebird
Firebirdの推奨コネクタライブラリはsqlalchemy-firebirdです。Supersetはsqlalchemy-firebird>=0.7.0, <0.8でテスト済みです。
推奨される接続文字列は次のとおりです。
firebird+fdb://{username}:{password}@{host}:{port}//{path_to_db_file}
SupersetがローカルのFirebirdデータベースに接続する接続文字列の例を次に示します。
firebird+fdb://SYSDBA:masterkey@192.168.86.38:3050//Library/Frameworks/Firebird.framework/Versions/A/Resources/examples/empbuild/employee.fdb
Firebolt
Fireboltの推奨コネクタライブラリはfirebolt-sqlalchemyです。
推奨される接続文字列は次のとおりです。
firebolt://{username}:{password}@{database}?account_name={name}
or
firebolt://{username}:{password}@{database}/{engine_name}?account_name={name}
サービスアカウントを使用して接続することもできます。
firebolt://{client_id}:{client_secret}@{database}?account_name={name}
or
firebolt://{client_id}:{client_secret}@{database}/{engine_name}?account_name={name}
Google BigQuery
BigQueryの推奨コネクタライブラリはsqlalchemy-bigqueryです。
BigQueryドライバーのインストール
docker composeを使用してローカルでSupersetを設定する際に、新しいデータベースドライバーをインストールする方法については、こちらの手順に従ってください。
echo "sqlalchemy-bigquery" >> ./docker/requirements-local.txt
BigQueryへの接続
Supersetに新しいBigQuery接続を追加するときは、GCPサービスアカウントの認証情報ファイル(JSON形式)を追加する必要があります。
- Google Cloud Platformコントロールパネルからサービスアカウントを作成し、適切なBigQueryデータセットへのアクセスを提供し、サービスアカウントのJSON構成ファイルをダウンロードします。
- Supersetでは、そのJSONをアップロードするか、次の形式でJSON BLOBを追加できます(これは認証情報JSONファイルの内容である必要があります)。
{
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}
-
さらに、SQLAlchemy URI経由で接続することもできます。
BigQueryの接続文字列は次のようになります。
bigquery://{project_id}[詳細]タブに移動し、次の形式でデータベース構成フォームの[セキュアな追加]フィールドにJSON BLOBを追加します。
{
"credentials_info": <contents of credentials JSON file>
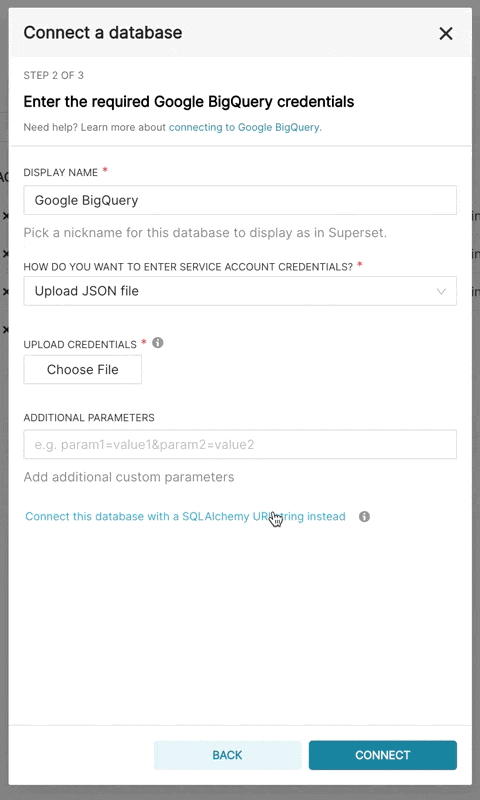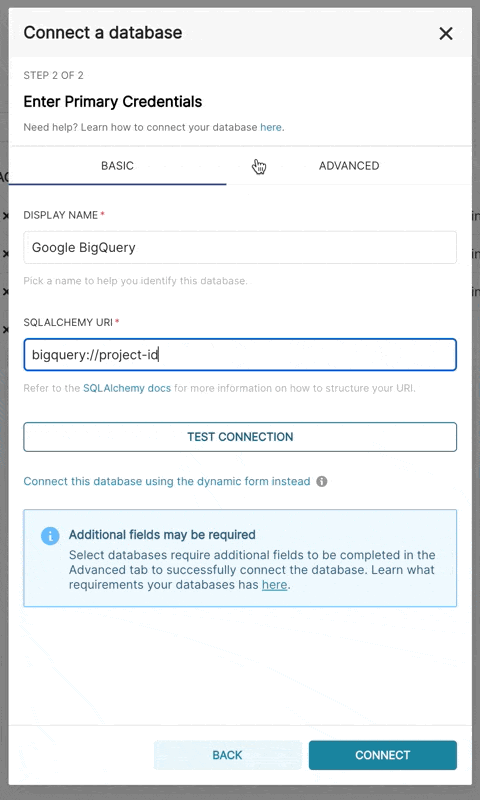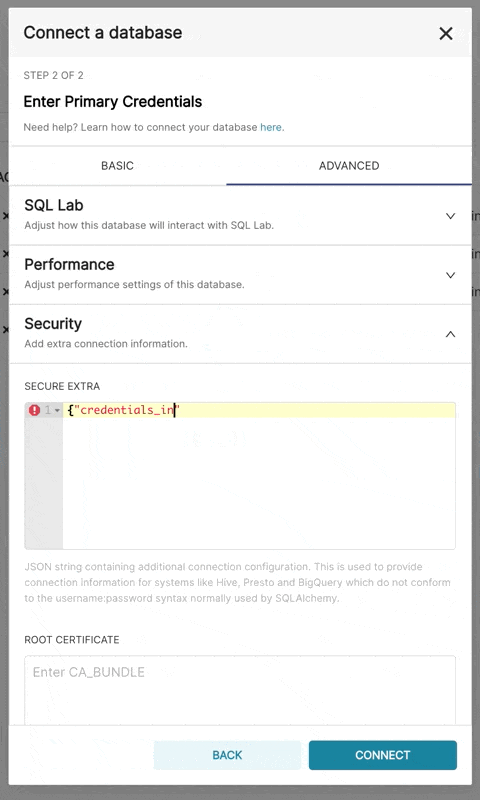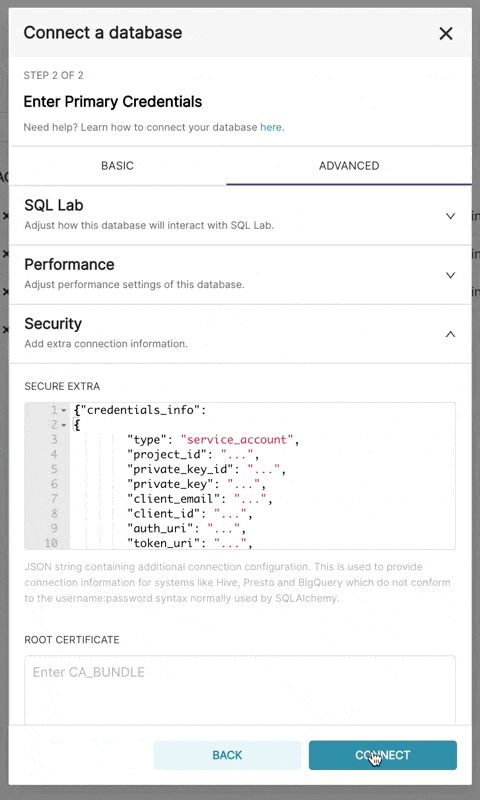
}結果のファイルは次の構造になります。
{
"credentials_info": {
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}
}
これで、BigQueryデータセットに接続できるはずです。
SupersetでCSVまたはExcelファイルをBigQueryにアップロードできるようにするには、pandas_gbqライブラリも追加する必要があります。
現在、Google BigQuery Python SDKは、geventによるpythonコアライブラリの動的なモンキーパッチのため、geventと互換性がありません。したがって、gunicornサーバーでSupersetをデプロイする場合は、gevent以外のワーカータイプを使用する必要があります。
Google Sheets
Google Sheetsには、非常に制限されたSQL APIがあります。Google Sheetsの推奨コネクタライブラリはshillelaghです。
SupersetをGoogle Sheetsに接続するには、いくつかの手順が必要です。こちらのチュートリアルには、この接続の設定に関する最新の説明があります。
Hana
推奨コネクタライブラリはsqlalchemy-hanaです。
接続文字列は次のようにフォーマットされます。
hana://{username}:{password}@{host}:{port}
Apache Hive
pyhiveライブラリは、SQLAlchemyを介してHiveに接続する推奨方法です。
予期される接続文字列は、次のようにフォーマットされます。
hive://hive@{hostname}:{port}/{database}
Hologres
Hologresは、Alibaba Cloudによって開発されたリアルタイムのインタラクティブ分析サービスです。PostgreSQL 11と完全に互換性があり、ビッグデータエコシステムとシームレスに統合されています。
Hologresの接続パラメーターの例
- ユーザー名:Alibaba CloudアカウントのAccessKey ID。
- パスワード:Alibaba CloudアカウントのAccessKeyシークレット。
- データベースホスト:Hologresインスタンスのパブリックエンドポイント。
- データベース名:Hologresデータベースの名前。
- ポート:Hologresインスタンスのポート番号。
接続文字列は次のようになります。
postgresql+psycopg2://{username}:{password}@{host}:{port}/{database}
IBM DB2
IBM_DB_SAライブラリは、IBM Data ServersへのPython/SQLAlchemyインターフェースを提供します。
推奨される接続文字列を次に示します。
db2+ibm_db://{username}:{passport}@{hostname}:{port}/{database}
SQLAlchemyには、2つのDB2ダイアレクトバージョンが実装されています。LIMIT [n]構文のないDB2バージョンに接続する場合、SQL Labを使用できるようにするための推奨接続文字列は次のとおりです。
ibm_db_sa://{username}:{passport}@{hostname}:{port}/{database}
Apache Impala
Apache Impalaへの推奨コネクタライブラリはimpylaです。
予期される接続文字列は、次のようにフォーマットされます。
impala://{hostname}:{port}/{database}
Kusto
Kusto で推奨されるコネクターライブラリは、sqlalchemy-kusto>=2.0.0 です。
Kusto (sql ダイアレクト) の接続文字列は以下のようになります。
kustosql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=False
Kusto (kql ダイアレクト) の接続文字列は以下のようになります。
kustokql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=False
ユーザーが必要なすべてのデータベース/テーブル/ビューにアクセスして使用する権限を持っていることを確認してください。
Apache Kylin
Apache Kylin で推奨されるコネクターライブラリは kylinpy です。
予期される接続文字列は、次のようにフォーマットされます。
kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2>
MySQL
MySQL で推奨されるコネクターライブラリは mysqlclient です。
以下に接続文字列を示します。
mysql://{username}:{password}@{host}/{database}
ホスト
- ローカルホストの場合:
localhostまたは127.0.0.1 - Linux で実行されている Docker:
172.18.0.1 - オンプレミスの場合: IP アドレスまたはホスト名
- OSX で実行されている Docker の場合:
docker.for.mac.host.internalポート: デフォルトでは3306
mysqlclient の問題点の 1 つは、クライアントにプラグインが含まれていないため、認証に caching_sha2_password を使用する新しい MySQL データベースへの接続に失敗することです。この場合、代わりに mysql-connector-python を使用する必要があります。
mysql+mysqlconnector://{username}:{password}@{host}/{database}
IBM Netezza Performance Server
nzalchemy ライブラリは、IBM Netezza Performance Server (別名 Netezza) への Python / SQLAlchemy インターフェースを提供します。
推奨される接続文字列を次に示します。
netezza+nzpy://{username}:{password}@{hostname}:{port}/{database}
OceanBase
sqlalchemy-oceanbase ライブラリは、SQLAlchemy を介して OceanBase に接続するための推奨される方法です。
OceanBase の接続文字列は以下のようになります。
oceanbase://<User>:<Password>@<Host>:<Port>/<Database>
Ocient DB
Ocient で推奨されるコネクターライブラリは sqlalchemy-ocient です。
Ocient ドライバーのインストール
pip install sqlalchemy-ocient
Ocient への接続
Ocient DSN の形式は次のとおりです。
ocient://user:password@[host][:port][/database][?param1=value1&...]
Oracle
推奨されるコネクターライブラリは cx_Oracle です。
接続文字列は次のようにフォーマットされます。
oracle://<username>:<password>@<hostname>:<port>
Apache Pinot
Apache Pinot で推奨されるコネクターライブラリは pinotdb です。
予期される接続文字列は、次のようにフォーマットされます。
pinot+http://<pinot-broker-host>:<pinot-broker-port>/query?controller=http://<pinot-controller-host>:<pinot-controller-port>/``
ユーザー名とパスワードを使用する際の予想される接続文字列の形式は次のとおりです。
pinot://<username>:<password>@<pinot-broker-host>:<pinot-broker-port>/query/sql?controller=http://<pinot-controller-host>:<pinot-controller-port>/verify_ssl=true``
探索ビューや結合、ウィンドウ関数などを使用する場合は、マルチステージクエリエンジンを有効にしてください。[Advanced -> Other -> ENGINE PARAMETERS]でデータベース接続を作成する際に、以下の引数を追加してください。
{"connect_args":{"use_multistage_engine":"true"}}
Postgres
docker compose を使用している場合、Postgres コネクターライブラリ psycopg2 は Superset に同梱されていることに注意してください。
Postgres の接続パラメータのサンプル
- ユーザー名: ユーザー名
- パスワード: DBパスワード
- データベースホスト:
- ローカルホストの場合: localhost または 127.0.0.1
- オンプレミスの場合: IP アドレスまたはホスト名
- AWS エンドポイントの場合
- データベース名: データベース名
- ポート: デフォルト 5432
接続文字列は次のようになります。
postgresql://{username}:{password}@{host}:{port}/{database}
最後に ?sslmode=require を追加することで SSL を必須にできます。
postgresql://{username}:{password}@{host}:{port}/{database}?sslmode=require
Postgres がサポートするその他の SSL モードについては、このドキュメントの表 31-1 を参照してください。
PostgreSQL 接続オプションの詳細については、SQLAlchemy のドキュメント および PostgreSQL のドキュメントを参照してください。
Presto
pyhive ライブラリは、SQLAlchemy を介して Presto に接続するための推奨される方法です。
予期される接続文字列は、次のようにフォーマットされます。
presto://{hostname}:{port}/{database}
ユーザー名とパスワードも渡すことができます。
presto://{username}:{password}@{hostname}:{port}/{database}
以下に値を使用した接続文字列の例を示します。
presto://datascientist:securepassword@presto.example.com:8080/hive
Superset はデフォルトで、データソースのクエリ時に最新バージョンの Presto が使用されていると想定します。古いバージョンの Presto を使用している場合は、追加パラメータで設定できます。
{
"version": "0.123"
}
SSL セキュアな追加は、追加の接続情報に JSON 設定を追加します。
{
"connect_args":
{"protocol": "https",
"requests_kwargs":{"verify":false}
}
}
RisingWave
RisingWave で推奨されるコネクターライブラリは sqlalchemy-risingwave です。
予期される接続文字列は、次のようにフォーマットされます。
risingwave://root@{hostname}:{port}/{database}?sslmode=disable
Rockset
Rockset の接続文字列は次のとおりです。
rockset://{api key}:@{api server}
Rockset コンソールから API キーを取得してください。API リファレンスから API サーバーを探してください。URL の https:// 部分は省略してください。
特定の仮想インスタンスをターゲットにするには、次の URI 形式を使用します。
rockset://{api key}:@{api server}/{VI ID}
より詳しい手順については、Rockset のドキュメントを参照することをお勧めします。
Snowflake
Snowflake ドライバーのインストール
docker compose を使用して Superset をローカルでセットアップする際に新しいデータベースドライバーをインストールする方法については、こちらの手順に従ってください。
echo "snowflake-sqlalchemy" >> ./docker/requirements-local.txt
Snowflake で推奨されるコネクターライブラリは snowflake-sqlalchemy です。
Snowflake の接続文字列は以下のようになります。
snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse}
スキーマはテーブル/クエリごとに定義されるため、接続文字列では必須ではありません。ユーザーにデフォルトが定義されている場合、ロールとウェアハウスは省略できます。例:
snowflake://{user}:{password}@{account}.{region}/{database}
Snowflake SQLAlchemy エンジンはデフォルトではエンジン作成中にユーザー/ロールの権限をテストしないため、ユーザーが必要なすべてのデータベース/スキーマ/テーブル/ビュー/ウェアハウスにアクセスして使用する権限を持っていることを確認してください。ただし、データベース作成または編集ダイアログで「接続テスト」ボタンを押すと、エンジン作成中に connect() メソッドに “validate_default_parameters”: True が渡されることで、ユーザー/ロールの資格情報が検証されます。ユーザー/ロールがデータベースへのアクセスを許可されていない場合、エラーが Superset のログに記録されます。
また、キーペア認証で Snowflake に接続したい場合は、キーペアを持っていることと、公開キーが Snowflake に登録されていることを確認してください。キーペア認証で Snowflake に接続するには、以下のパラメーターを "SECURE EXTRA" フィールドに追加する必要があります。
複数行のプライベートキーの内容を 1 行にマージし、各行の間に \n を挿入する必要があることに注意してください。
{
"auth_method": "keypair",
"auth_params": {
"privatekey_body": "-----BEGIN ENCRYPTED PRIVATE KEY-----\n...\n...\n-----END ENCRYPTED PRIVATE KEY-----",
"privatekey_pass":"Your Private Key Password"
}
}
プライベートキーがサーバーに保存されている場合は、パラメーターの "privatekey_body" を "privatekey_path" に置き換えることができます。
{
"auth_method": "keypair",
"auth_params": {
"privatekey_path":"Your Private Key Path",
"privatekey_pass":"Your Private Key Password"
}
}
Apache Solr
sqlalchemy-solr ライブラリは、Apache Solr への Python / SQLAlchemy インターフェースを提供します。
Solr の接続文字列は以下のようになります。
solr://{username}:{password}@{host}:{port}/{server_path}/{collection}[/?use_ssl=true|false]
Apache Spark SQL
Apache Spark SQL で推奨されるコネクターライブラリは pyhive です。
予期される接続文字列は、次のようにフォーマットされます。
hive://hive@{hostname}:{port}/{database}
SQL Server
SQL Server で推奨されるコネクターライブラリは pymssql です。
SQL Server の接続文字列は以下のようになります。
mssql+pymssql://<Username>:<Password>@<Host>:<Port-default:1433>/<Database Name>/?Encrypt=yes
pyodbc を使用して、パラメータ odbc_connect を使用して接続することもできます。
SQL Server の接続文字列は以下のようになります。
mssql+pyodbc:///?odbc_connect=Driver%3D%7BODBC+Driver+17+for+SQL+Server%7D%3BServer%3Dtcp%3A%3Cmy_server%3E%2C1433%3BDatabase%3Dmy_database%3BUid%3Dmy_user_name%3BPwd%3Dmy_password%3BEncrypt%3Dyes%3BConnection+Timeout%3D30
StarRocks
sqlalchemy-starrocks ライブラリは、SQLAlchemy を介して StarRocks に接続するための推奨される方法です。
接続文字列を形成するには、次の設定値が必要になります。
- User: ユーザー名
- パスワード: DBパスワード
- ホスト: StarRocks FE ホスト
- Catalog: カタログ名
- Database: データベース名
- ポート: StarRocks FE ポート
接続文字列は次のようになります。
starrocks://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>
StarRocks は、Superset のドキュメントをこちらで維持しています。
Teradata
推奨されるコネクターライブラリは teradatasqlalchemy です。
Teradata の接続文字列は以下のようになります。
teradatasql://{user}:{password}@{host}
ODBC ドライバー
ODBC ドライバーのインストールが必要な sqlalchemy-teradata という古いコネクターもあります。Teradata ODBC ドライバーは、こちらで入手できます: https://downloads.teradata.com/download/connectivity/odbc-driver/linux
必要な環境変数は次のとおりです。
export ODBCINI=/.../teradata/client/ODBC_64/odbc.ini
export ODBCINST=/.../teradata/client/ODBC_64/odbcinst.ini
ODBC ドライバーに関する要件がなく、より定期的に更新されるため、最初のライブラリを使用することをお勧めします。
TimescaleDB
TimescaleDB は、強力なデータ集約型アプリケーションを構築するための、時系列データと分析用のオープンソースのリレーショナルデータベースです。TimescaleDB は PostgreSQL の拡張機能であり、標準の PostgreSQL コネクターライブラリである psycopg2 を使用してデータベースに接続できます。
docker compose を使用している場合、psycopg2 は Superset に同梱されています。
TimescaleDB の接続パラメータのサンプル
- ユーザー名: ユーザー
- Password: パスワード
- データベースホスト:
- ローカルホストの場合: localhost または 127.0.0.1
- オンプレミスの場合: IP アドレスまたはホスト名
- Timescale Cloud サービスの場合: ホスト名
- Managed Service for TimescaleDB サービスの場合: ホスト名
- データベース名: データベース名
- ポート: デフォルト 5432 またはサービスのポート番号
接続文字列は次のようになります。
postgresql://{username}:{password}@{host}:{port}/{database name}
最後に ?sslmode=require を追加することで SSL を必須にできます (例: Timescale Cloud を使用する場合)。
postgresql://{username}:{password}@{host}:{port}/{database name}?sslmode=require
Trino
Trino バージョン 352 以降をサポート
接続文字列
接続文字列の形式は次のとおりです。
trino://{username}:{password}@{hostname}:{port}/{catalog}
ローカルマシンで Docker を使用して Trino を実行している場合は、次の接続 URL を使用してください。
trino://trino@host.docker.internal:8080
認証
1. ベーシック認証
接続文字列またはAdvanced / SecurityのSecure Extraフィールドにusername/passwordを指定できます。
-
接続文字列の場合
trino://{username}:{password}@{hostname}:{port}/{catalog} -
Secure Extraフィールドの場合{
"auth_method": "basic",
"auth_params": {
"username": "<username>",
"password": "<password>"
}
}
注: 両方が指定されている場合、Secure Extraが常に優先されます。
2. Kerberos認証
Secure Extraフィールドに、以下の例のように設定します。
{
"auth_method": "kerberos",
"auth_params": {
"service_name": "superset",
"config": "/path/to/krb5.config",
...
}
}
auth_params内のすべてのフィールドは、KerberosAuthenticationクラスに直接渡されます。
注: Kerberos認証には、allまたはkerberosオプション機能のいずれかを使用して、trino-python-clientをローカルにインストールする必要があります。つまり、それぞれtrino[all]またはtrino[kerberos]をインストールします。
3. 証明書認証
Secure Extraフィールドに、以下の例のように設定します。
{
"auth_method": "certificate",
"auth_params": {
"cert": "/path/to/cert.pem",
"key": "/path/to/key.pem"
}
}
auth_params内のすべてのフィールドは、CertificateAuthenticationクラスに直接渡されます。
4. JWT認証
auth_methodを設定し、Secure Extraフィールドにトークンを提供します。
{
"auth_method": "jwt",
"auth_params": {
"token": "<your-jwt-token>"
}
}
5. カスタム認証
カスタム認証を使用するには、まずSuperset設定ファイルのALLOWED_EXTRA_AUTHENTICATIONS許可リストに追加する必要があります。
from your.module import AuthClass
from another.extra import auth_method
ALLOWED_EXTRA_AUTHENTICATIONS: Dict[str, Dict[str, Callable[..., Any]]] = {
"trino": {
"custom_auth": AuthClass,
"another_auth_method": auth_method,
},
}
次に、Secure Extraフィールドに以下のように設定します。
{
"auth_method": "custom_auth",
"auth_params": {
...
}
}
trino.auth.Authenticationクラスまたはファクトリ関数(Authenticationインスタンスを返す)への参照をauth_methodに指定して、カスタム認証を使用することもできます。
auth_params内のすべてのフィールドは、クラス/関数に直接渡されます。
参考:
Vertica
推奨されるコネクタライブラリはsqlalchemy-vertica-pythonです。Verticaの接続パラメータは次のとおりです。
- ユーザー名: ユーザー名
- パスワード: DBパスワード
- データベースホスト
- ローカルホストの場合: localhost または 127.0.0.1
- オンプレミスの場合: IPアドレスまたはホスト名
- クラウドの場合: IPアドレスまたはホスト名
- データベース名: データベース名
- ポート: デフォルト 5433
接続文字列は次のようにフォーマットされます。
vertica+vertica_python://{username}:{password}@{host}/{database}
その他のパラメータ
- ロードバランサー - バックアップホスト
YugabyteDB
YugabyteDBは、PostgreSQLをベースに構築された分散SQLデータベースです。
docker compose を使用している場合、Postgres コネクターライブラリ psycopg2 は Superset に同梱されていることに注意してください。
接続文字列は次のようになります。
postgresql://{username}:{password}@{host}:{port}/{database}
UI経由での接続
新しいDB接続UIを活用する方法に関するドキュメントはこちらです。これにより、新しいデータベースに接続したいユーザーのUXを向上させる機能が管理者に追加されます。
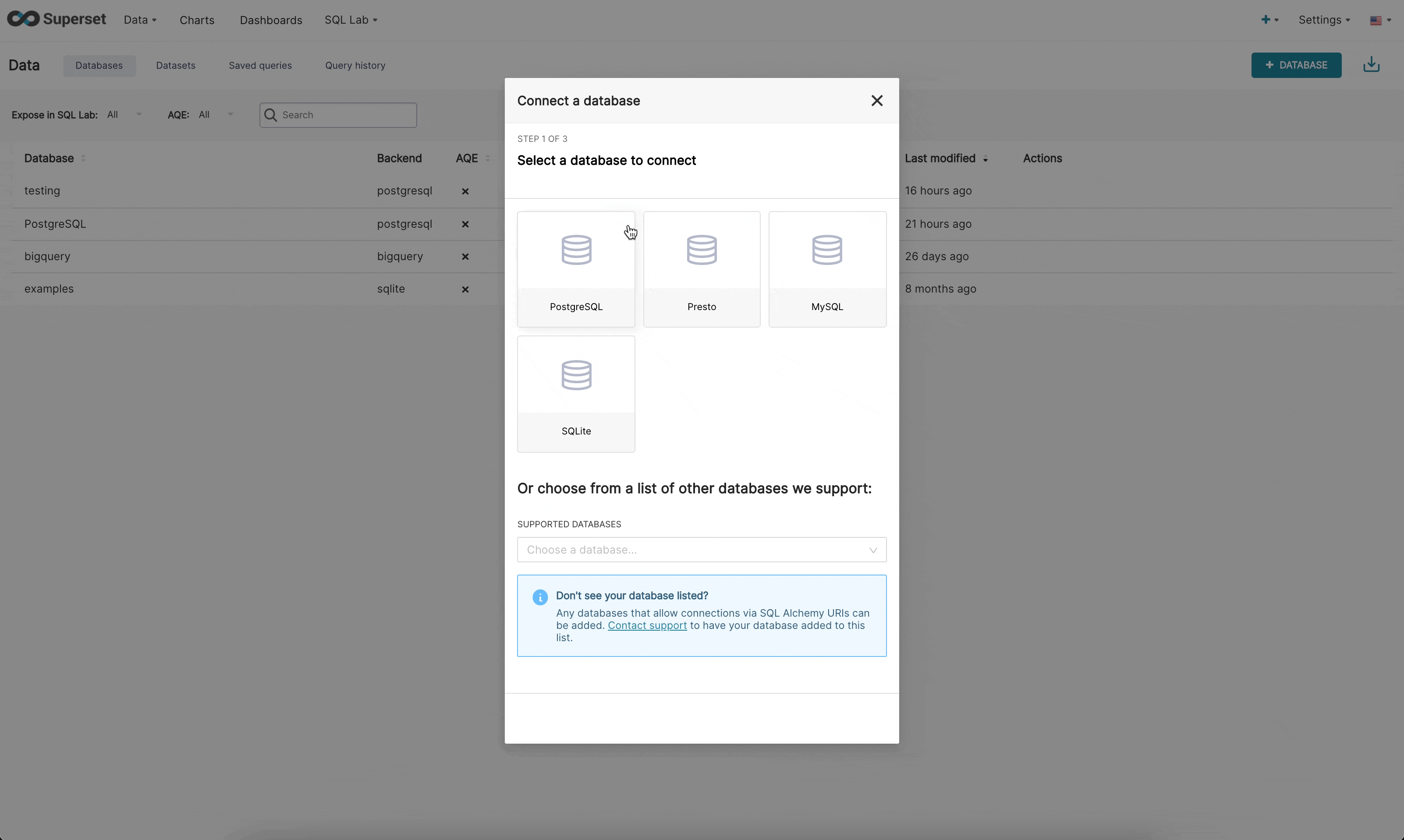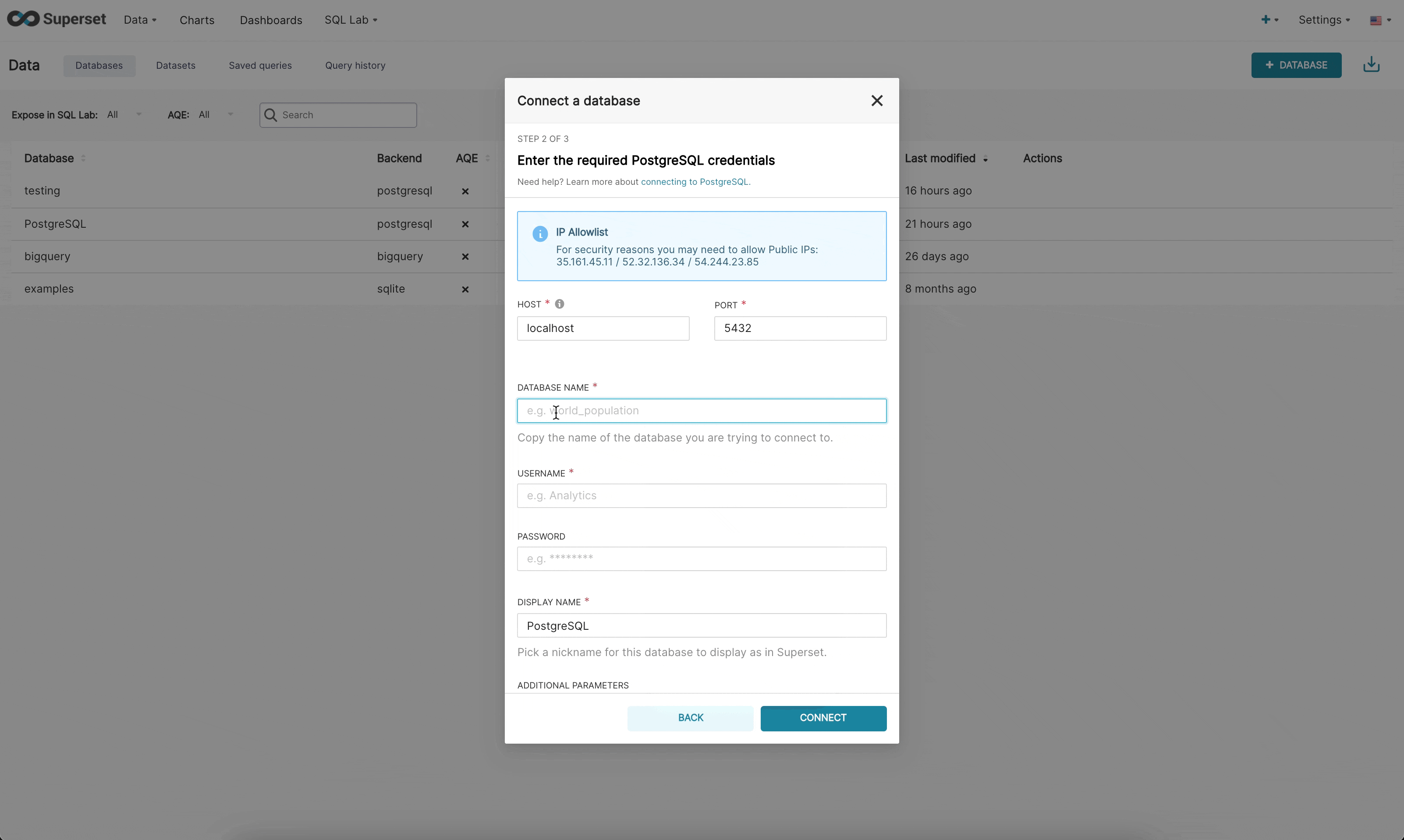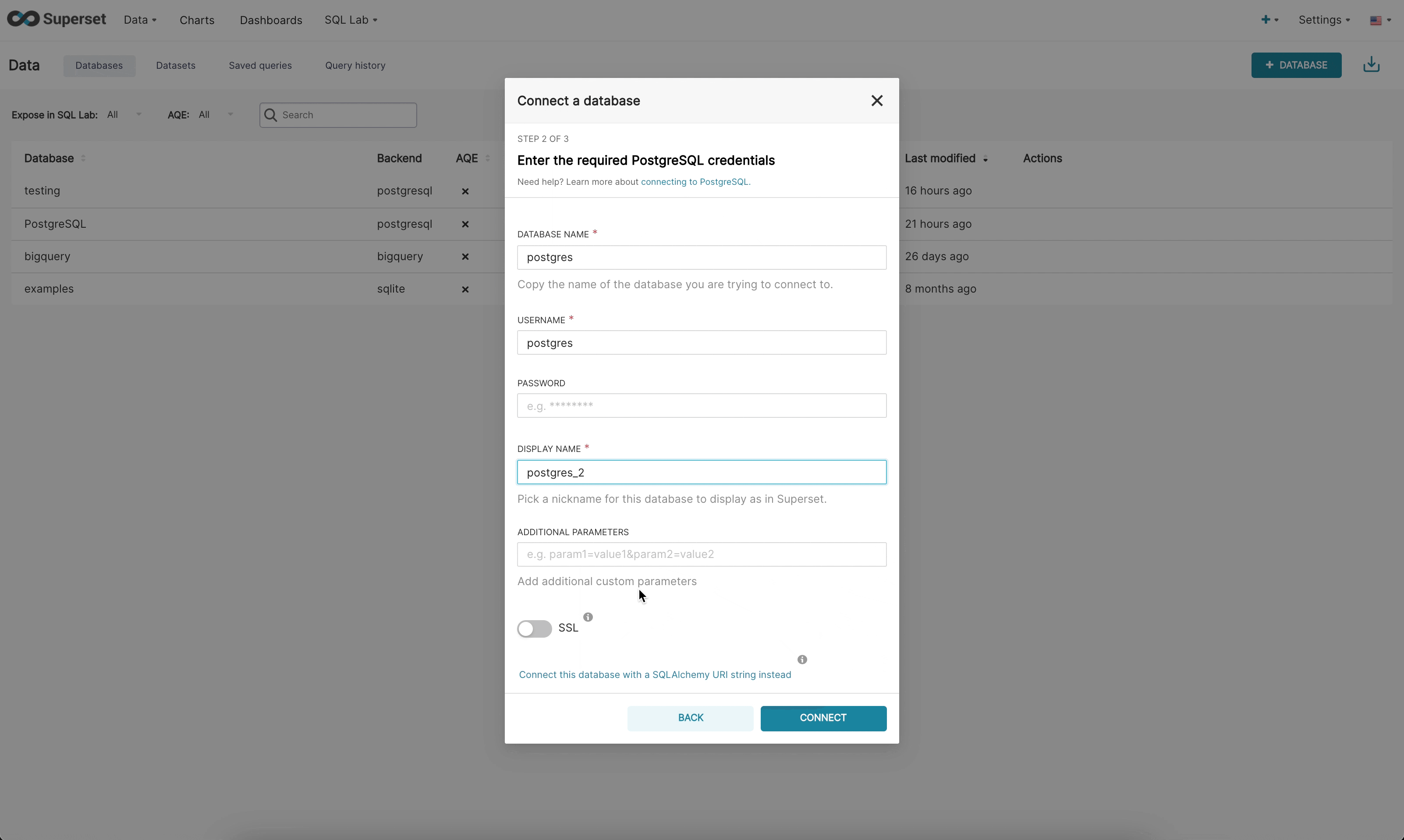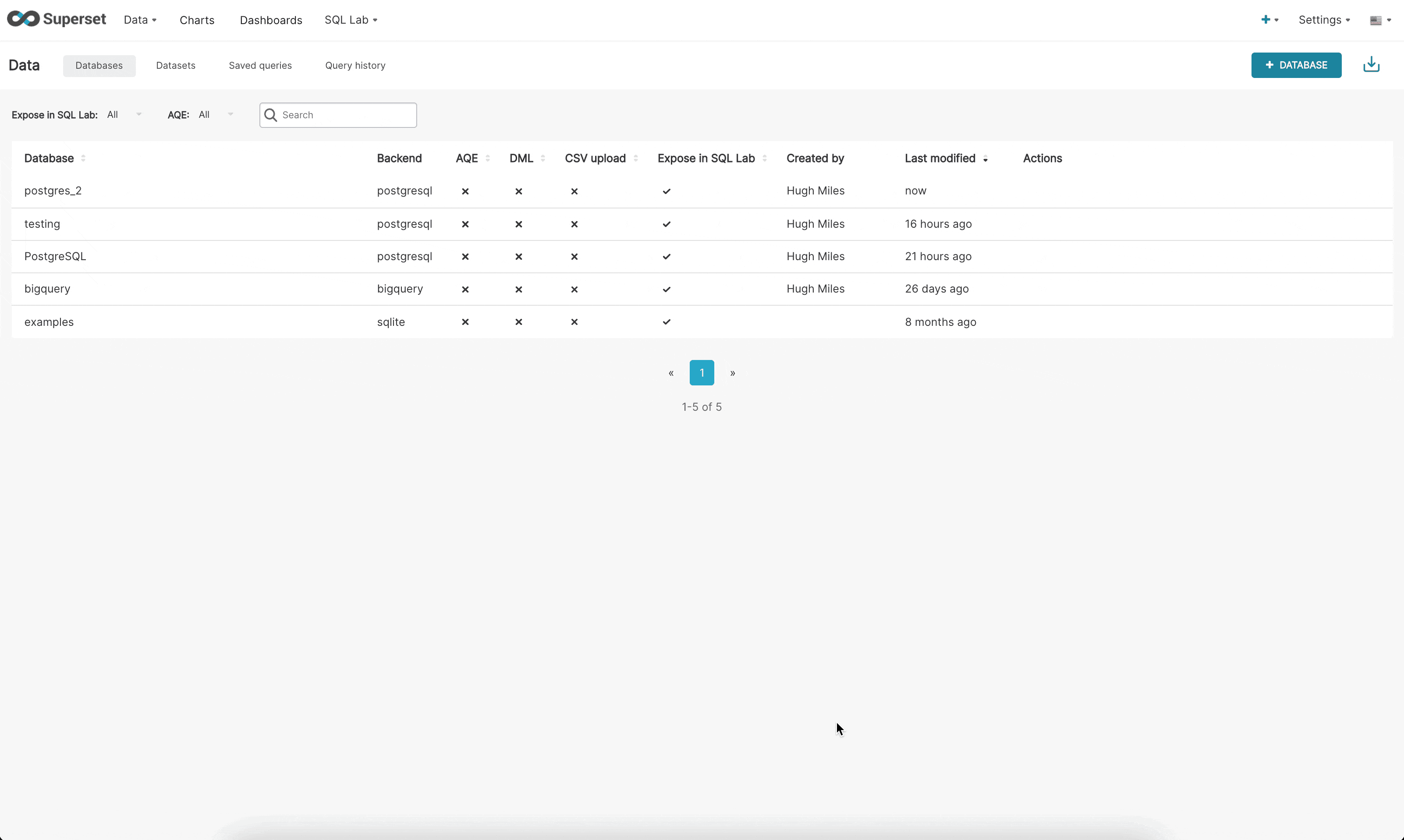
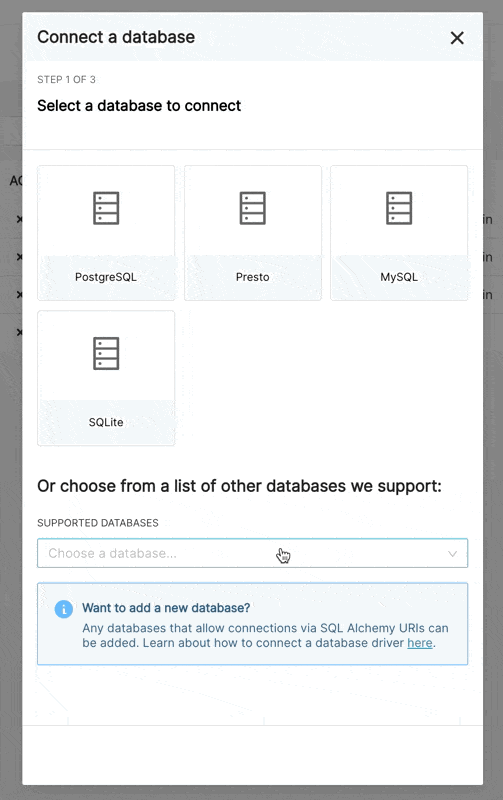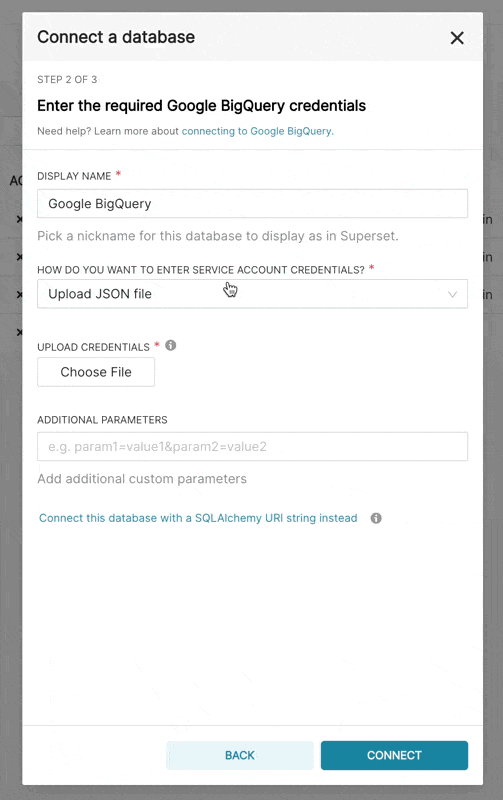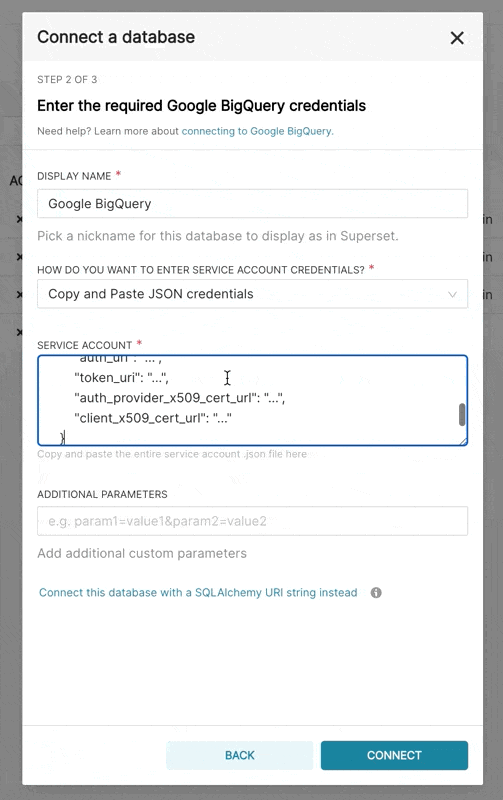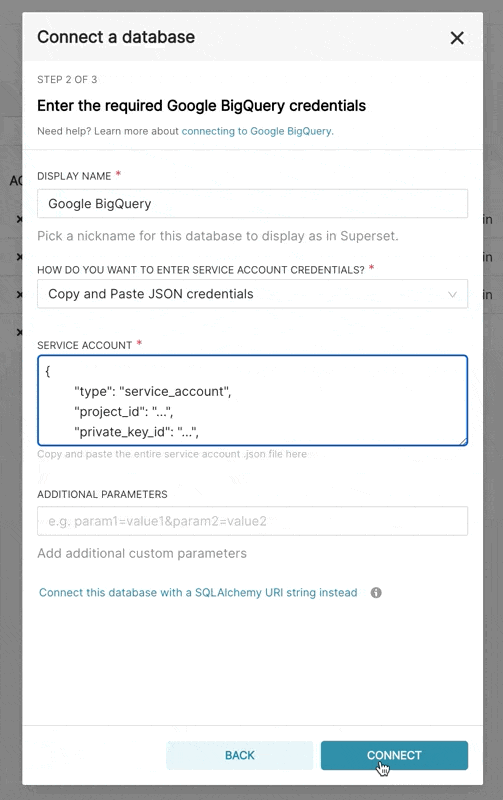
新しいUIでデータベースに接続する場合、3つのステップがあります。
ステップ1: まず、管理者は接続したいエンジンをSupersetに通知する必要があります。このページは、環境に現在インストールされているエンジンをプルする/availableエンドポイントによって駆動されるため、サポートされているデータベースのみが表示されます。
ステップ2: 次に、管理者はデータベース固有のパラメータを入力するように求められます。特定のエンジンで動的フォームが利用可能かどうかによって、管理者は新しいカスタムフォームまたは従来のSQLAlchemyフォームのいずれかを確認します。(Redshift、MySQL、Postgres、BigQuery)用に動的フォームを構築しました。新しいフォームでは、接続に必要なパラメータ(たとえば、ユーザー名、パスワード、ホスト、ポートなど)がユーザーに求められ、エラーに関する即時のフィードバックが提供されます。
ステップ3: 最後に、管理者が動的フォームを使用してDBに接続したら、オプションの高度な設定を更新する機会があります。
この機能により、ユーザーがアプリケーションに参加してデータセットの作成を開始するためのボトルネックが大幅に解消されることを願っています。
推奨データベースオプションとイメージの設定方法
管理者が推奨データベースを順に定義できる新しい構成オプションを追加しました。
# A list of preferred databases, in order. These databases will be
# displayed prominently in the "Add Database" dialog. You should
# use the "engine_name" attribute of the corresponding DB engine spec
# in `superset/db_engine_specs/`.
PREFERRED_DATABASES: list[str] = [
"PostgreSQL",
"Presto",
"MySQL",
"SQLite",
]
著作権上の理由により、各データベースのロゴはSupersetとともに配布されません。
イメージの設定
- 推奨データベースのイメージを設定するには、管理者は
superset_text.ymlファイルで、エンジンとイメージの場所のマッピングを作成する必要があります。イメージは、静的/ファイルディレクトリ内でローカルにホストすることも、オンライン(S3など)でホストすることもできます。
DB_IMAGES:
postgresql: "path/to/image/postgres.jpg"
bigquery: "path/to/s3bucket/bigquery.jpg"
snowflake: "path/to/image/snowflake.jpg"
使用可能なエンドポイントに新しいデータベースエンジンを追加する方法
現在、新しいモーダルは次のデータベースをサポートしています。
- Postgres
- Redshift
- MySQL
- BigQuery
ユーザーがこのリストにないデータベースを選択すると、SQLAlchemy URIを要求する古いダイアログが表示されます。新しいデータベースは、新しいフローに徐々に追加できます。リッチな構成をサポートするには、DBエンジン仕様に次の属性が必要です。
parameters_schema: データベースを構成するために必要なパラメータを定義するMarshmallowスキーマ。Postgresの場合、これにはユーザー名、パスワード、ホスト、ポートなどが含まれます(参照)。default_driver: DBエンジン仕様の推奨ドライバーの名前。多くのSQLAlchemyダイアレクトは複数のドライバーをサポートしていますが、通常、1つが公式の推奨です。Postgresの場合、"psycopg2"を使用します。sqlalchemy_uri_placeholder: ユーザーがURIを直接入力したい場合に役立つ文字列。encryption_parameters: ユーザーが暗号化された接続を選択した場合に、URIを構築するために使用されるパラメータ。Postgresの場合、これは{"sslmode": "require"}です。
さらに、DBエンジン仕様は次のクラスメソッドを実装する必要があります。
build_sqlalchemy_uri(cls, parameters, encrypted_extra): このメソッドは、個別のパラメータを受け取り、それらからURIを構築します。get_parameters_from_uri(cls, uri, encrypted_extra): このメソッドは逆のことを行い、特定のURIからパラメータを抽出します。validate_parameters(cls, parameters): このメソッドは、フォームのonBlur検証に使用されます。どのパラメータが欠落しているか、どのパラメータが確実に間違っているかを示すSupersetErrorのリストを返す必要があります(例)。
engine+driver://user:password@host:port/dbnameの標準形式を使用するMySQLやPostgresのようなデータベースの場合、必要なのはDBエンジン仕様にBasicParametersMixinを追加し、パラメータ2〜4を定義することだけです(parameters_schemaはすでにmixinに存在します)。
他のデータベースの場合は、これらのメソッドを自分で実装する必要があります。BigQuery DBエンジン仕様は、その方法の良い例です。
追加のデータベース設定
より深いSQLAlchemy統合
SQLAlchemyによって公開されたパラメータを使用して、データベース接続情報を調整することができます。データベース編集ビューで、ExtraフィールドをJSON blobとして編集できます。
このJSON文字列には、追加の構成要素が含まれています。engine_paramsオブジェクトはsqlalchemy.create_engine呼び出しに展開され、metadata_paramsはsqlalchemy.MetaData呼び出しに展開されます。詳細については、SQLAlchemyドキュメントを参照してください。
スキーマ
PostgresやRedshiftなどのデータベースは、データベースの上にスキーマを論理エンティティとして使用します。Supersetが特定のスキーマに接続するには、テーブルの編集フォーム(ソース > テーブル > レコードの編集)でスキーマパラメータを設定できます。
SQLAlchemy接続用の外部パスワードストア
Supersetは、データベースパスワードの外部ストアを使用するように構成できます。これは、カスタムシークレット配布フレームワークを実行していて、Supersetのメタデータベースにシークレットを保存したくない場合に役立ちます。
例: 型がsqla.engine.urlの単一の引数を取り、指定された接続文字列のパスワードを返す関数を作成します。次に、構成ファイルでSQLALCHEMY_CUSTOM_PASSWORD_STOREをその関数を指すように設定します。
def example_lookup_password(url):
secret = <<get password from external framework>>
return 'secret'
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_lookup_password
一般的なパターンは、環境変数を使用してシークレットを利用できるようにすることです。SQLALCHEMY_CUSTOM_PASSWORD_STOREもその目的で使用できます。
def example_password_as_env_var(url):
# assuming the uri looks like
# mysql://?superset_user:{SUPERSET_PASSWORD}
return url.password.format(**os.environ)
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_password_as_env_var
データベースへのSSLアクセス
データベースの編集フォームのExtraフィールドを使用してSSLを構成できます。
{
"metadata_params": {},
"engine_params": {
"connect_args":{
"sslmode":"require",
"sslrootcert": "/path/to/my/pem"
}
}
}
その他
データベース間のクエリ
Supersetは、異なるデータベース間でクエリを実行するための実験的な機能を提供しています。これは、「superset://」SQLAlchemy URIを使用する「Supersetメタデータベース」と呼ばれる特別なデータベースを介して行われます。データベースを使用すると、次の構文を使用して、構成されたデータベースの任意のテーブルに対してクエリを実行できます。
SELECT * FROM "database name.[[catalog.].schema].table name";
例:
SELECT * FROM "examples.birth_names";
スペースは許可されますが、名前のピリオドは%2Eに置き換える必要があります。例:
SELECT * FROM "Superset meta database.examples%2Ebirth_names";
上記のクエリはSELECT * FROM "examples.birth_names"と同じ行を返し、メタデータベースが任意のテーブル(それ自体も含む)からテーブルをクエリできることも示しています。
考慮事項
この機能を有効にする前に、考慮すべき点がいくつかあります。まず、メタデータベースはクエリされたテーブルに対するアクセス許可を強制するため、ユーザーは元々アクセス権を持っているテーブルにのみデータベース経由でアクセスできる必要があります。それにもかかわらず、メタデータベースは潜在的な攻撃の新しい表面であり、バグによりユーザーが見てはいけないデータを見ることができる可能性があります。
次に、パフォーマンスに関する考慮事項があります。メタデータベースは、フィルタリング、ソート、および制限を基盤となるデータベースにプッシュしますが、集計および結合は、クエリを実行しているプロセス内のメモリで発生します。このため、データベースを非同期モードで実行して、クエリがWebワーカーではなくCeleryワーカーで実行されるようにすることをお勧めします。さらに、基盤となるデータベースから返される行数にハードリミットを指定することができます。
メタデータベースの有効化
Supersetメタデータベースを有効にするには、まずENABLE_SUPERSET_META_DBフィーチャーフラグをtrueに設定する必要があります。次に、SQLAlchemy URI「superset://」を使用して、タイプ「Supersetメタデータベース」の新しいデータベースを追加します。
メタデータベースでDMLを有効にすると、ユーザーは、DMLがそれらでも有効になっている限り、基盤となるデータベースに対してDMLクエリを実行できるようになります。これにより、ユーザーはデータベース間でデータを移動するクエリを実行できます。
次に、SUPERSET_META_DB_LIMIT の値を変更したい場合があります。デフォルト値は 1000 で、集計や結合が実行される前に各データベースから読み込まれるレコード数を定義します。テーブルが小さい場合は、この値を None に設定することもできます。
さらに、メタデータベースがアクセスできるデータベースを制限したい場合があります。これは、データベース構成の「Advanced」->「Other」->「ENGINE PARAMETERS」で、以下を追加することで行えます。
{"allowed_dbs":["Google Sheets","examples"]}